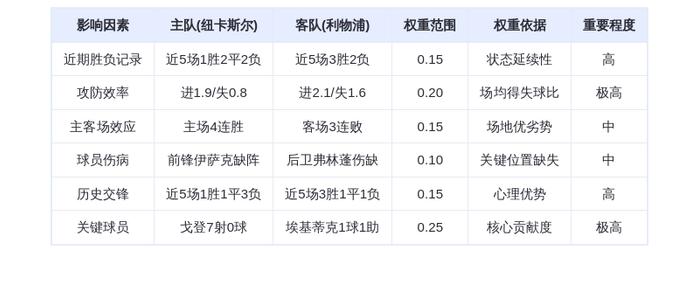
700万参数击败DeepSeek R1等,三星一人独作爆火,用递归颠覆大模型推理
今年 6 月,来自 Sapient Intelligence 的研究者提出了分层推理模型(HRM),用循环架构打破了传统思维链(CoT)的架构限制,对大模型推理结构产生了重大的影响。HRM 仅包含 2700 万个参数(大约比最小的 Qwen3 0.6B 模型小 22 倍)
这个 TRM 有多离谱呢?一个仅包含 700万个参数(比HRM 还要小 4 倍)的网络,在某些最困难的推理基准测试中,其参数数量与 o3-mini 和 Gemini 2.5 Pro 等尖端语言模型相比,甚至可以超越它们,尽管这些模型的参数数量是 TRM 的 10,000 倍。
论文作者 Jolicoeur-Martineau 说:「通过递归推理,结果证明 『少即是多』。一个从头开始预训练的小模型,通过递归自身并在时间推移中更新答案,可以在不超出预算的情况下取得很大成果。」
1.起草初始答案:不同于逐字生成的普通大语言模型(LLM),TRM 首先会快速生成一个完整的「草稿答案」,可以理解为它的第一次粗略猜测。
3.深入自我审查:模型进入一个高强度的内循环。它不断将草稿答案与原始问题进行对比,在草稿板上反复(连续 6 次)推敲和修正推理逻辑,不断自问:「我的逻辑是否成立?错误在哪里?」
4.修订答案:经过这段专注的「思考」后,模型会利用在草稿板中改进后的逻辑,重新生成一个全新的、更高质量的最终答案草稿。
5.循环至自信为止:整个「起草 — 思考 — 修订」的过程最多可重复 16 次。每一轮迭代都让模型更接近一个正确且逻辑严密的解决方案。
HRM 假设其递归过程在 z_L 和 z_H 上都会收敛到某个不动点,以便使用 一步梯度近似(1-step gradient approximation)为了绕开这种理论上的约束,TRM 重新定义了「完整的递归过程」:
在训练中,先运行 T−1 次无梯度的递归过程 来改进 (z_L, z_H),然后再运行一次带反向传播的递归过程。
换句话说,不再使用一步梯度近似,而是采用包含 n 次 f_L 与一次 f_H 的完整递归更新,从而完全消除了对不动点假设和隐函数定理(IFT)的一步梯度近似的依赖。
自注意力机制(Self-Attention)在长上下文场景表现出色,因为它只需一个形状为 [D, 3D] 的参数矩阵,却能建模整个序列的全局依赖。
然而,在短上下文任务中,使用线性层(Linear Layer)更加高效,仅需一个形状为 [L, L] 的参数矩阵即可完成建模。
受到 MLP-Mixer 的启发,将自注意力层替换为作用于序列维度上的多层感知机(MLP)。
从实验结果可以看出,不带自注意力机制的 TRM 在 Sudoku-Extreme 上表现最佳,测试准确率达 87.4%。而 带自注意力机制的 TRM 在其他任务上泛化效果更好deepseek。
相比之下,使用 4 倍参数量(2700 万) 的 HRM 模型仅达到 74.5%、40.3% 和 5.0% 的准确率,显示出 TRM 在参数效率与泛化能力上的显著优势。原文出处:700万参数击败DeepSeek R1等,三星一人独作爆火,用递归颠覆大模型推理,感谢原作者,侵权必删!